Strategie vor Code: Data & AI Consulting, das in der Produktion hält
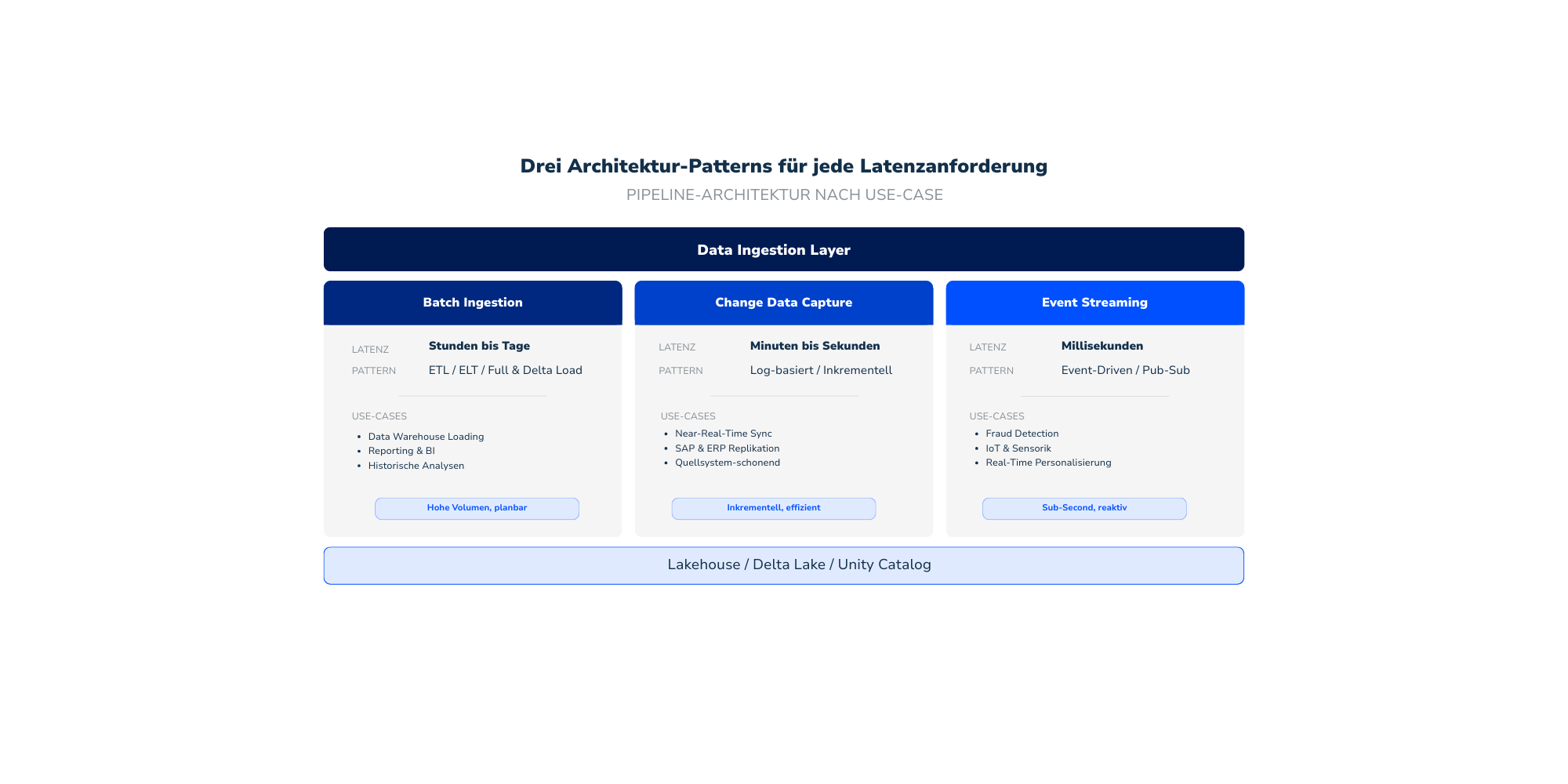
Production-Grade Data Engineering: Batch- und Streaming-Pipelines, ML-Modelle und Data Products; als Software gebaut, nicht als Notebook-Prototyp.



Engineering, das messbaren Business-Impact schafft
Ohne Implementierung ist eine Datenplattform wie ein leeres Fundament. Selbst die beste Lakehouse-Architektur ist wertlos, wenn niemand die Pipelines erstellt, die Daten integriert, die Modelle operationalisiert und die Ergebnisse für Business-User zugänglich macht.
Die Infrastruktur ist zwar die Grundlage, aber der Business-Impact wird im Engineering geschaffen: in den Pipelines, die Rohdaten in verlässliche Entscheidungsgrundlagen umwandeln, in den Modellen, die Vorhersagen in Echtzeit liefern, und in den Data Products, die Geschäftslogik als Code darstellen.
Wir setzen die Wertschöpfung auf eurer Datenplattform um; von Batch-Pipelines über Event-Driven Streaming bis hin zu produktionsreifen ML-Modellen und Self-Service Analytics.




.png)