ANSI-SQL; kein proprietärer Dialekt
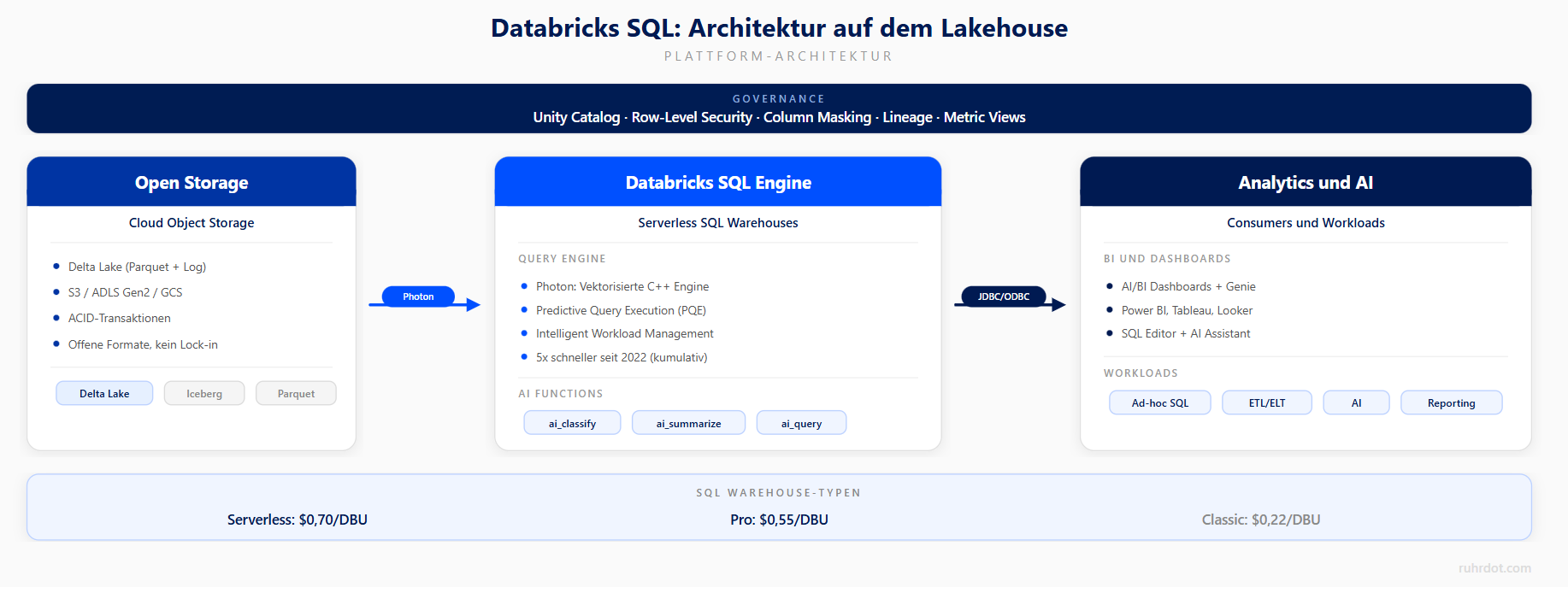
Databricks SQL spricht standardkonformes ANSI SQL. Wer SELECT, JOIN, GROUP BY, Window Functions oder CTEs kennt, schreibt sofort produktive Queries – ohne neue Syntax zu lernen. Das senkt die Einstiegshürde für BI-Analysten und Data Engineers gleichermaßen, und bestehende SQL-Skripte aus anderen Warehouses lassen sich in den meisten Fällen ohne Anpassung migrieren.
Integrierter SQL Editor mit AI-Unterstützung
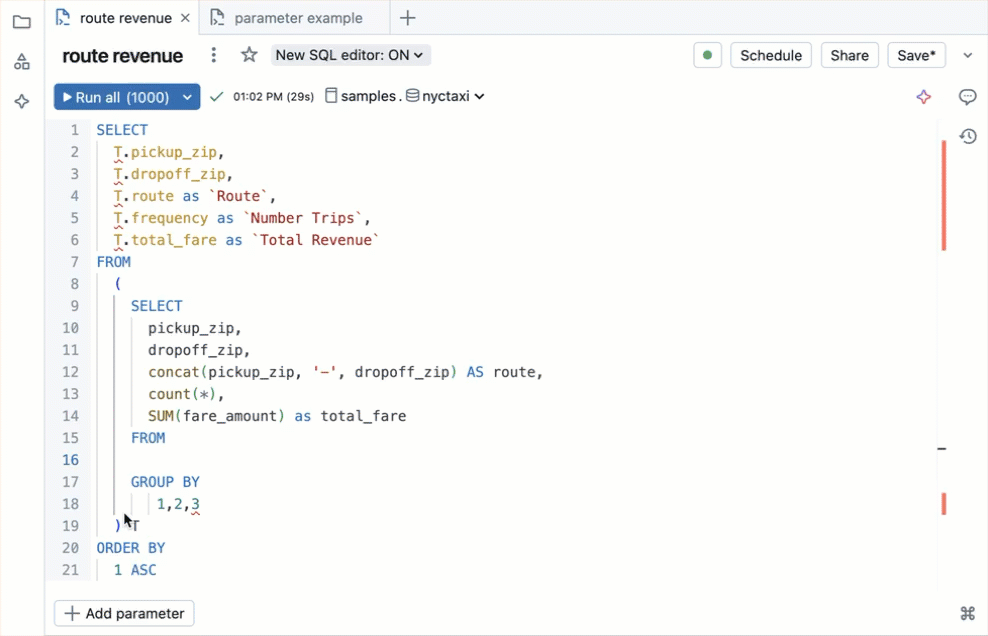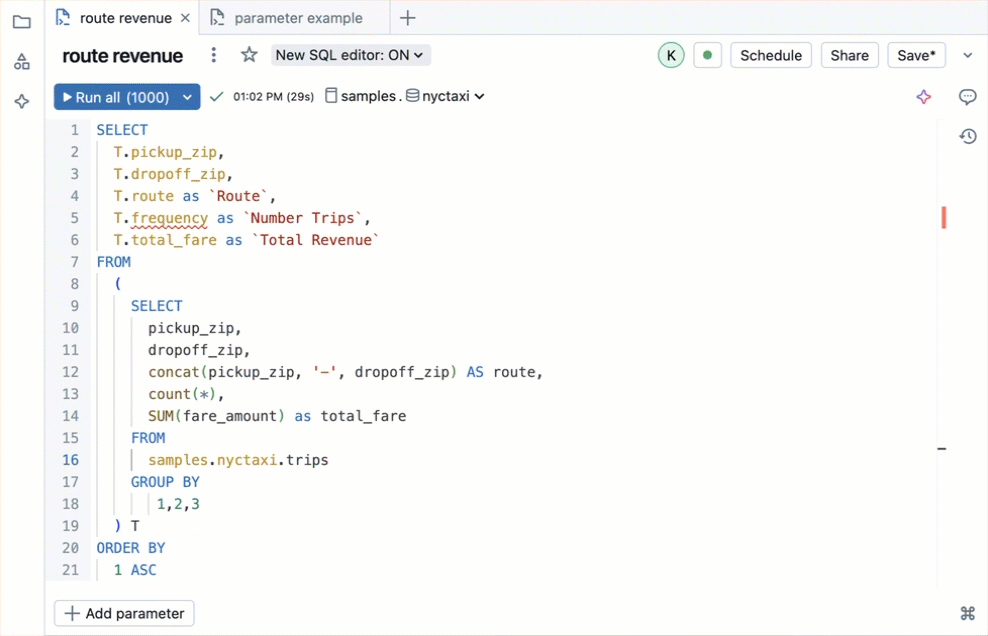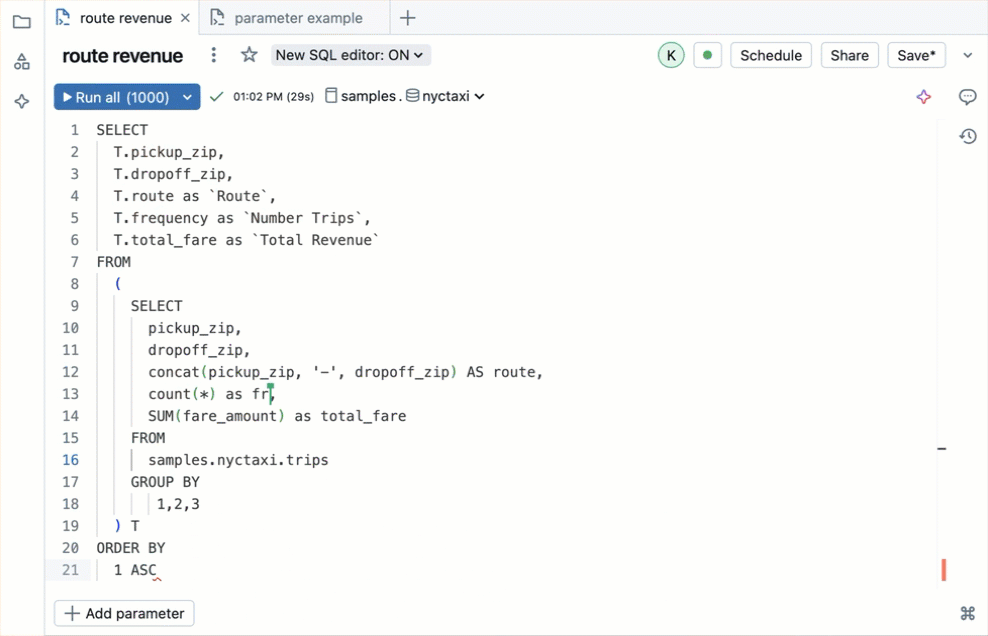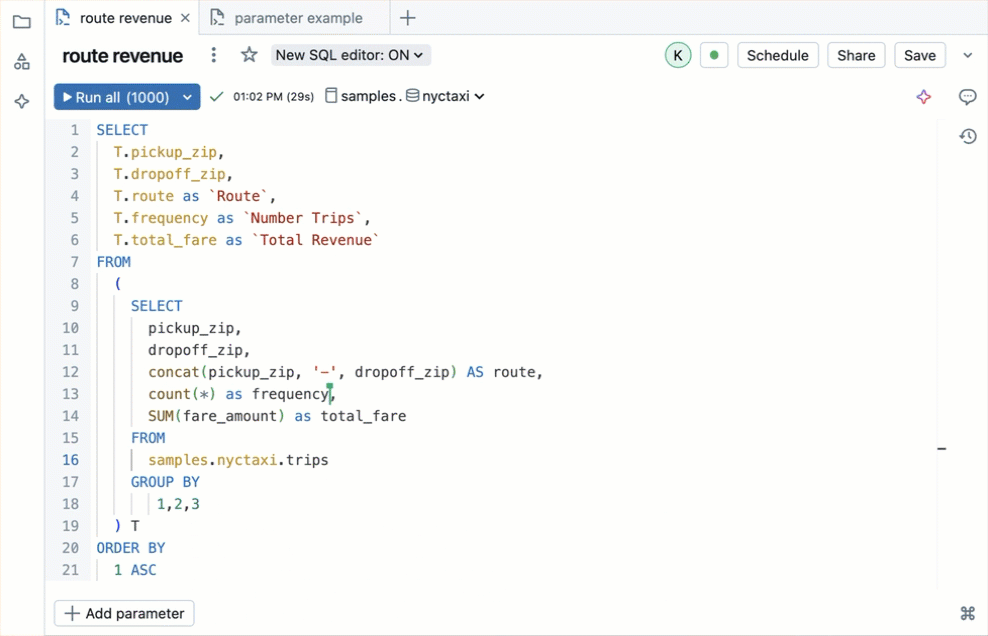
Databricks bringt einen vollwertigen SQL Editor direkt in der Web-Oberfläche mit: Syntax-Highlighting, kontextabhängiges Autocomplete (erkennt Tabellen, Spalten und Aliase aus Unity Catalog), Multi-Tab-Editing und integrierte Visualisierungen. Ergebnisse lassen sich direkt als Chart rendern oder per Klick in ein AI/BI Dashboard überführen.
Seit dem neuen Editor kommt der Databricks Assistant als AI-Copilot dazu: er generiert SQL aus natürlichsprachlichen Beschreibungen, optimiert bestehende Queries über den /optimize-Befehl und erklärt komplexe Statements. Für komplexere Aufgaben gibt es Genie Code, einen autonomen KI-Agenten, der mehrstufige Analysen selbstständig durchführt. Dazu kommen Echtzeit-Kollaboration (mehrere Nutzer arbeiten gleichzeitig an derselben Query), Code-Kommentare und Versionierung – Features, die man sonst nur aus dedizierten IDEs kennt. (Siehe Aufnahme unterhalb des Textes)
Unity Catalog als zentraler Datenkatalog
Der SQL Editor ist nativ in Unity Catalog integriert: der Schema-Browser zeigt alle Catalogs, Schemas und Tabellen, auf die der Nutzer Zugriff hat – mit Spaltentypen, Beschreibungen und Lineage-Informationen. Ihr navigiert den gesamten Datenkatalog direkt im Editor, ohne zwischen Tools wechseln zu müssen. Unity Catalog gilt plattformweit: BI-Analysten im SQL Editor sehen exakt dieselben Tabellen und Berechtigungen wie Data Engineers in Notebooks oder ML-Engineers in Feature Stores.